Excel có ba hàm tính phân bố xác suất F, và nhiều người nhầm lẫn giữa chúng. Hàm F.DIST xuất hiện từ Excel 2010, thay thế hàm FDIST cũ với độ chính xác cao hơn. Điểm khác biệt chính nằm ở tham số thứ tư, cho phép bạn chọn giữa hàm phân bố tích lũy hoặc hàm mật độ xác suất. Khi biết cách dùng đúng, bạn tiết kiệm thời gian so sánh mức đa dạng giữa hai tập dữ liệu.
Cú pháp hàm F.DIST
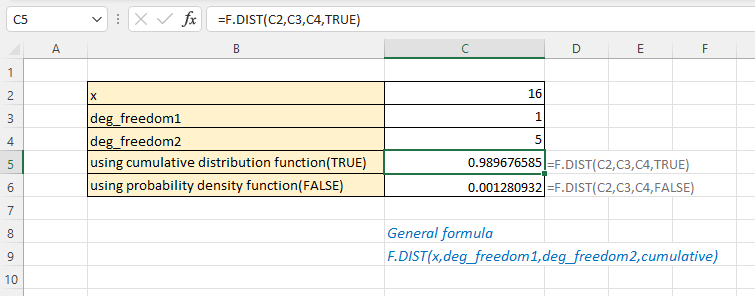
Hàm F.DIST yêu cầu bốn tham số bắt buộc theo thứ tự cố định.
Cấu trúc chuẩn:
=F.DIST(x, deg_freedom1, deg_freedom2, cumulative)Giải thích từng tham số:
- x: Giá trị để đánh giá hàm, phải là số dương
- deg_freedom1: Bậc tự do của tử số, thường từ tập dữ liệu thứ nhất
- deg_freedom2: Bậc tự do của mẫu số, từ tập dữ liệu thứ hai
- cumulative: Chọn TRUE cho hàm phân bố tích lũy, FALSE cho hàm mật độ xác suất
Khi nhập deg_freedom1 hoặc deg_freedom2 là số thập phân, Excel tự động cắt bỏ phần lẻ. Ví dụ nhập 5.8 sẽ được tính là 5. Hai bậc tự do này phải lớn hơn hoặc bằng 1, nếu nhỏ hơn 1 sẽ nhận lỗi #NUM!.
F.DIST khác gì với F.DIST.RT và FDIST
Ba hàm này đều tính phân bố xác suất F nhưng cho kết quả khác nhau.
F.DIST tính xác suất từ đuôi trái của đường cong phân bố. Với cumulative = TRUE, nó trả về xác suất mà biến ngẫu nhiên F nhỏ hơn hoặc bằng giá trị x. Hàm này linh hoạt nhất vì cho phép chọn cả hàm tích lũy lẫn hàm mật độ.
F.DIST.RT chỉ tính xác suất từ đuôi phải, tương đương với công thức P(F > x). Hàm này thay thế trực tiếp hàm FDIST cũ với cú pháp tương tự, chỉ khác tên. Khi phân tích ANOVA hoặc kiểm định F, đa số trường hợp cần dùng F.DIST.RT.
FDIST là phiên bản cũ, vẫn tồn tại trong Excel để tương thích ngược với các file từ Excel 2007 trở về trước. Microsoft khuyến cáo không nên dùng FDIST cho các bảng tính mới vì có thể bị loại bỏ trong phiên bản Excel tương lai.
Để chuyển đổi giữa F.DIST và F.DIST.RT, dùng công thức: F.DIST.RT(x,…) = 1 – F.DIST(x,…,TRUE). Với phân tích thống kê chuẩn, F.DIST.RT thường được ưu tiên vì kết quả trực tiếp cho giá trị p-value.
Ví dụ tính xác suất F với cumulative = TRUE
Giả sử bạn đang so sánh điểm kiểm tra của hai nhóm học sinh. Nhóm A có 10 học sinh, nhóm B có 12 học sinh. Sau khi tính toán, bạn có giá trị F là 2.5.
Để tính xác suất mà giá trị F nhỏ hơn hoặc bằng 2.5:
=F.DIST(2.5, 9, 11, TRUE)Kết quả trả về khoảng 0.935, nghĩa là có 93.5% xác suất giá trị F nhỏ hơn 2.5 với bậc tự do 9 và 11. Công thức này hữu ích khi bạn cần biết xác suất tích lũy từ điểm đầu đến giá trị cụ thể.
Lưu ý deg_freedom1 = n1 – 1 = 10 – 1 = 9, và deg_freedom2 = n2 – 1 = 12 – 1 = 11. Với phân tích phương sai, bậc tự do tử số thường là số nhóm trừ 1, bậc tự do mẫu số là tổng số quan sát trừ số nhóm.
Ví dụ với cumulative = FALSE
Khi cần giá trị tại một điểm cụ thể trên đường cong phân bố, đổi tham số cuối thành FALSE:
=F.DIST(2.5, 9, 11, FALSE)Kết quả khoảng 0.158, đây là giá trị hàm mật độ xác suất tại điểm F = 2.5. Hàm này ít dùng hơn trong phân tích thống kê thực tế, nhưng cần thiết khi vẽ đồ thị phân bố F hoặc tính toán trong lý thuyết xác suất.
Sự khác biệt: cumulative = TRUE cho diện tích dưới đường cong từ 0 đến x, còn cumulative = FALSE cho chiều cao của đường cong tại điểm x.
Lỗi #NUM! và cách khắc phục
Lỗi #NUM! xuất hiện khi giá trị x âm hoặc bậc tự do nhỏ hơn 1.
Các trường hợp phổ biến:
- Nhập x = -2.5: Phân bố F chỉ định nghĩa với giá trị dương
- deg_freedom1 = 0: Bậc tự do tối thiểu là 1
- deg_freedom2 quá lớn: Vượt quá 10^10 (trường hợp hiếm)
Cách fix: Kiểm tra lại công thức tính giá trị F và bậc tự do. Nếu dùng tham chiếu ô, đảm bảo các ô chứa số dương. Với tập dữ liệu có n quan sát, bậc tự do thường là n – 1, không bao giờ bằng 0 hoặc âm.
Lỗi #VALUE! khi nhập sai kiểu dữ liệu
Khi một trong bốn tham số là văn bản thay vì số, Excel trả về #VALUE!.
=F.DIST("2.5", 9, 11, TRUE) → Lỗi #VALUE! vì "2.5" là text
=F.DIST(A1, 9, 11, TRUE) → Lỗi #VALUE! nếu A1 chứa textCách khắc phục nhanh: Dùng hàm VALUE() để chuyển text thành số:
=F.DIST(VALUE(A1), 9, 11, TRUE)Hoặc kiểm tra định dạng ô trước khi nhập công thức. Nhấp chuột phải vào ô, chọn Format Cells, đảm bảo định dạng là Number chứ không phải Text. Lỗi này thường xuất hiện khi import dữ liệu từ CSV hoặc copy từ nguồn bên ngoài.
Lưu ý khi sử dụng trong phân tích ANOVA
Phân tích phương sai một yếu tố với k nhóm và N tổng quan sát:
- deg_freedom1 = k – 1 (giữa các nhóm)
- deg_freedom2 = N – k (trong các nhóm)
Sau khi tính giá trị F từ tỷ số phương sai, dùng F.DIST.RT để tìm giá trị p:
=F.DIST.RT(giá_trị_F, k-1, N-k)Nếu kết quả nhỏ hơn 0.05, bác bỏ giả thuyết không có sự khác biệt giữa các nhóm. Tôi thường dùng công thức này để xác minh kết quả từ Data Analysis Toolpak, đặc biệt khi cần tính toán động trên bảng tính lớn.
Version và tương thích
Hàm F.DIST hoạt động từ Excel 2010, Excel 2013, Excel 2016, Excel 2019, Excel 2021 và Microsoft 365. Các phiên bản cũ hơn như Excel 2007 chỉ có hàm FDIST.
Khi mở file chứa F.DIST trên Excel 2007, hàm sẽ hiển thị lỗi #NAME! vì không nhận diện được. Để tương thích ngược, giữ song song hai công thức: F.DIST cho Excel mới và FDIST cho Excel cũ, hoặc yêu cầu người dùng nâng cấp lên ít nhất Excel 2010.
Với phân tích dữ liệu thường xuyên, nên dùng F.DIST thay vì FDIST để đảm bảo độ chính xác cao hơn. Các thuật toán tính toán trong F.DIST được Microsoft cải tiến so với FDIST phiên bản cũ.