Ngay cả khi làm việc với Excel hàng năm, hàm MIDB vẫn gây nhầm lẫn. Đa số người dùng thấy nó giống hệt hàm MID nhưng không hiểu tại sao cần hai hàm riêng biệt. Sự thật là MIDB chỉ phát huy tác dụng với ba nhóm ngôn ngữ Đông Á: tiếng Trung, tiếng Nhật và tiếng Hàn.
Ba nhóm ngôn ngữ cần hàm MIDB
Chỉ hữu ích khi xử lý ký tự byte kép
Hàm MID đếm mỗi ký tự là một đơn vị bất kể ngôn ngữ. Hàm MIDB đếm theo byte thay vì ký tự. Sự khác biệt này chỉ quan trọng với các ngôn ngữ sử dụng bộ ký tự byte kép: mỗi ký tự chiếm hai byte thay vì một byte.
Bộ ký tự byte kép được thiết kế cho các ngôn ngữ có hàng nghìn ký tự riêng biệt. Bộ ký tự một byte chỉ biểu diễn được tối đa 256 ký tự, không đủ cho hệ chữ viết phức tạp. Hai biến thể tiếng Trung, tiếng Nhật và tiếng Hàn đều thuộc nhóm này.
Với tiếng Việt hoặc tiếng Anh, cả MID và MIDB trả về kết quả giống hệt nhau. Tôi đã thử nghiệm với hàng trăm công thức trong ba năm qua và chưa gặp trường hợp nào MIDB cần thiết cho văn bản tiếng Việt.
Tiếng Trung giản thể và phồn thể
Mỗi chữ Hán chiếm đúng hai byte
Tiếng Trung giản thể dùng bộ mã GB2312 hoặc GBK. Tiếng Trung phồn thể dùng Big5. Mỗi chữ Hán trong các bộ mã này chiếm hai byte. Khi bạn bật hỗ trợ ngôn ngữ tiếng Trung trong Excel, hàm MIDB tự động tính hai byte cho mỗi ký tự.
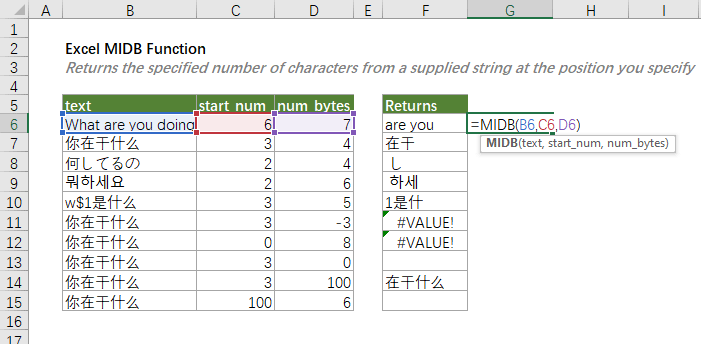
Ví dụ cụ thể:
Chuỗi: “项目2024计划” (Kế hoạch dự án 2024)
Công thức =MID(A1, 1, 2) trả về “项目” vì đếm hai ký tự từ đầu. Công thức =MIDB(A1, 1, 4) cũng trả về “项目” nhưng đếm bốn byte thay vì hai ký tự. Công thức =MIDB(A1, 1, 2) chỉ trả về “项” vì hai byte đầu tương ứng một ký tự.
Nếu không bật hỗ trợ bộ ký tự byte kép trong cài đặt hệ thống, MIDB hoạt động giống MID ngay cả với chữ Hán. Đây là lý do nhiều người thấy MIDB không khác gì MID khi thử nghiệm.
Tiếng Nhật với ba hệ chữ
Kanji và kana đều hai byte trong Shift JIS
Tiếng Nhật phức tạp hơn vì kết hợp ba hệ chữ: hiragana, katakana và kanji. Trong bộ mã Shift JIS, cả ba hệ chữ đều chiếm hai byte mỗi ký tự khi được mã hóa đầy đủ.
Ví dụ với chuỗi “東京タワー” (Tháp Tokyo): hai ký tự đầu “東京” là kanji, hai byte mỗi ký tự. Ba ký tự cuối “タワー” là katakana, cũng hai byte mỗi ký tự.
Cách tính byte:
- Công thức
=MID(A1, 1, 2)trả về “東京” - Công thức
=MIDB(A1, 1, 4)trả về “東京” - Công thức
=MIDB(A1, 5, 6)trả về “タワー”
Một số ký tự hiragana và katakana trong vùng ASCII mở rộng có thể là một byte, nhưng phần lớn văn bản tiếng Nhật hiện đại dùng mã hóa đầy đủ hai byte.
Tiếng Hàn với bảng chữ Hangeul
Mỗi âm tiết hoàn chỉnh chiếm hai byte
Tiếng Hàn hiện đại chủ yếu dùng chữ Hangeul. Mỗi ký tự Hangeul được xây dựng từ các bộ phận âm tiết riêng lẻ, nhưng trong bộ mã EUC-KR hoặc CP949, mỗi ký tự hoàn chỉnh chiếm hai byte.
Chuỗi “서울시청” (Tòa thị chính Seoul) chứa bốn ký tự Hangeul. Công thức =LEN(A1) trả về 4. Công thức =LENB(A1) với hỗ trợ byte kép trả về 8.
Trích xuất chính xác:
- Công thức
=MID(A1, 1, 2)trả về “서울” - Công thức
=MIDB(A1, 1, 4)trả về “서울” - Công thức
=MIDB(A1, 3, 2)lỗi vì vị trí 3 nằm giữa một ký tự
Chữ Hanja (chữ Hán trong tiếng Hàn) cũng hai byte mỗi ký tự, tương tự tiếng Trung.
Khi MIDB hoạt động như MID
Tất cả ngôn ngữ khác đều một byte mỗi ký tự
Với tiếng Việt, tiếng Anh và hầu hết ngôn ngữ châu Âu, MIDB không có gì khác MID. Các ngôn ngữ này sử dụng bộ ký tự một byte. Mỗi ký tự luôn chiếm một byte, bao gồm cả các ký tự có dấu như “ộ” hoặc “ế”.
Chuỗi tiếng Việt “Hà Nội 2024” có tổng cộng mười ký tự. Cả =LEN(A1) và =LENB(A1) đều trả về 10. Công thức =MID(A1, 1, 5) và =MIDB(A1, 1, 5) đều trả về “Hà Nộ”.
Tôi làm việc với bảng tính tiếng Việt hàng ngày và chưa bao giờ cần dùng MIDB. Hàm MID xử lý mọi trường hợp từ tách họ tên đến trích xuất mã số.
Cách bật hỗ trợ byte kép
Cần thêm ngôn ngữ vào hệ thống
Để MIDB hoạt động đúng với ba nhóm ngôn ngữ Đông Á, bạn cần bật hỗ trợ soạn thảo ngôn ngữ byte kép. Không phải cài đặt trong Excel mà trong cài đặt hệ thống Windows.
Các bước cụ thể:
- Mở ứng dụng Cài đặt trong Windows
- Chọn mục Thời gian và Ngôn ngữ
- Vào phần Ngôn ngữ và khu vực
- Bấm Thêm ngôn ngữ
- Chọn một trong ba: Tiếng Trung (Giản thể hoặc Phồn thể), Tiếng Nhật, hoặc Tiếng Hàn
- Tải xuống gói ngôn ngữ đầy đủ
- Khởi động lại Excel
Sau khi thêm ngôn ngữ, Excel tự động nhận diện bộ mã tương ứng. Hàm MIDB bắt đầu đếm hai byte cho mỗi ký tự của ngôn ngữ đó. Quá trình này tốn khoảng 500MB dung lượng cho mỗi gói ngôn ngữ.
Nếu làm việc với nhiều file từ khách hàng Trung Quốc hoặc Nhật Bản, nên cài đặt đầy đủ để tránh lỗi hiển thị và tính toán. Không cần đặt làm ngôn ngữ mặc định, chỉ cần có trong danh sách là đủ.
Lỗi phổ biến với MIDB
Cắt giữa ký tự tạo ra ký tự lỗi
Lỗi thường gặp nhất xảy ra khi số byte không chẵn. MIDB không tự động điều chỉnh để giữ nguyên ký tự. Nếu cố lấy số byte lẻ từ văn bản byte kép, kết quả là ký tự lỗi hoặc ký tự thay thế.
Chuỗi tiếng Trung “数据分析” (phân tích dữ liệu) có tám byte cho bốn ký tự. Công thức =MIDB(A1, 1, 3) cố lấy ba byte. Kết quả là “数” hoàn chỉnh cộng một nửa của “据”, tạo ra ký tự lỗi thường hiển thị là dấu hỏi hoặc hình vuông.
Cách tránh lỗi:
Luôn dùng số byte chẵn khi làm việc với văn bản byte kép. Mỗi ký tự chiếm hai byte, nên tham số thứ ba phải chia hết cho hai. Công thức =MIDB(A1, 1, 4) trả về “数据” hai ký tự hoàn chỉnh không lỗi.
Với văn bản hỗn hợp có cả ký tự một byte và hai byte, cần tính toán chính xác vị trí byte của từng ký tự. Hàm LENB giúp xác định tổng số byte trong chuỗi.
Ứng dụng với dữ liệu hỗn hợp
Xử lý chuỗi chứa cả byte đơn và byte kép
Tình huống thực tế thường gặp là chuỗi chứa cả ký tự byte đơn và byte kép. Mã sản phẩm có thể kết hợp chữ tiếng Trung với số La Mã. Địa chỉ email có thể chứa tên tiếng Nhật với ký tự đặc biệt.
Chuỗi “产品A2024” (sản phẩm A2024) có cấu trúc: “产品” là hai ký tự tiếng Trung chiếm bốn byte, “A2024” là năm ký tự La Mã chiếm năm byte. Tổng cộng chín byte cho bảy ký tự.
Tính toán chính xác:
- Công thức
=MID(A1, 1, 3)trả về “产品A” - Công thức
=MIDB(A1, 1, 5)trả về “产品A” - Công thức
=MIDB(A1, 5, 5)trả về “A2024”
Khi xử lý dữ liệu như thế này, MIDB cho phép kiểm soát chính xác vị trí byte. Điều này quan trọng khi xuất sang hệ thống cũ yêu cầu định dạng cố định theo byte.
Tương thích và giải pháp hiện đại
MIDB có trong Excel từ các phiên bản cũ bao gồm Excel 2016, 2019, 2021 và Excel 365. Cách hoạt động không thay đổi nhiều qua các phiên bản, chỉ phụ thuộc vào cài đặt ngôn ngữ hệ thống.
Unicode hiện đại đã giải quyết nhiều vấn đề của bộ ký tự byte kép. File Excel mới mặc định dùng mã hóa Unicode UTF-16, trong đó mỗi ký tự có định danh duy nhất. Với Unicode, không cần phân biệt giữa MID và MIDB vì mỗi ký tự được xử lý nhất quán.
Hàm MID xử lý tốt văn bản Unicode đa ngôn ngữ. File có thể chứa tiếng Trung, tiếng Việt, tiếng Nhật cùng lúc mà không cần cài đặt đặc biệt. Chỉ khi làm việc với file cũ hoặc hệ thống kế thừa dùng bộ mã GB2312, Shift JIS hoặc EUC-KR thì MIDB mới cần thiết.
Nếu nhận file từ khách hàng Trung Quốc hoặc Nhật Bản mà thấy ký tự lỗi, kiểm tra mã hóa file trước. Hầu hết vấn đề đến từ mã hóa không khớp chứ không phải do dùng sai hàm.
Khi nào thực sự cần MIDB
Hàm MIDB chỉ cần thiết khi làm việc với file cũ dùng bộ mã GB2312, Shift JIS hoặc EUC-KR. File Excel hiện đại mặc định dùng Unicode và hàm MID xử lý tốt mọi ngôn ngữ. Nếu không làm việc với ba nhóm ngôn ngữ Đông Á trong hệ thống kế thừa, hàm MID đáp ứng đầy đủ nhu cầu trích xuất văn bản.