Bảng tra cứu phân bố chuẩn chuẩn hóa dài 3 trang với hàng trăm giá trị giờ đây có thể bỏ hẳn. Hàm NORM.S.DIST trong Excel tính toán xác suất phân bố chuẩn chỉ trong vài giây với độ chính xác tuyệt đối. Từ Excel 2010 trở đi, hàm này thay thế hoàn toàn các bảng tra truyền thống và làm việc với dữ liệu thống kê nhanh hơn đáng kể.
Cú pháp đơn giản với 2 tham số
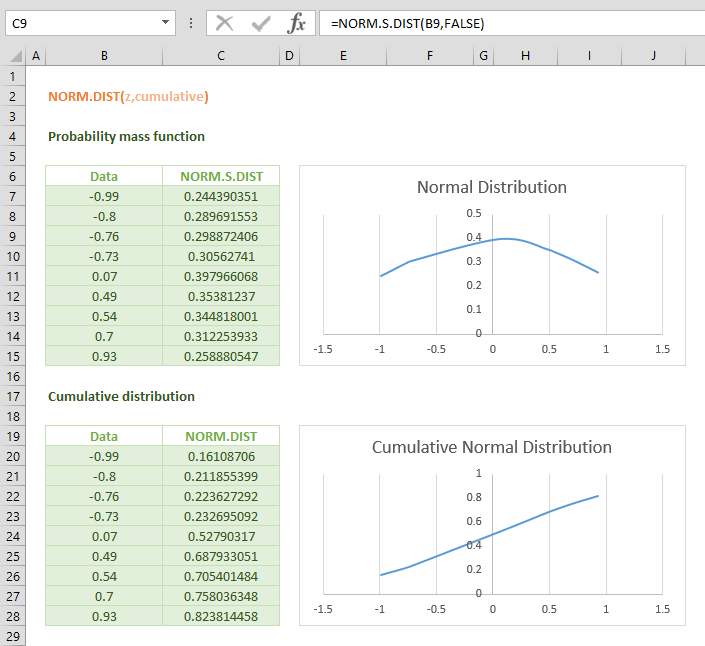
Hàm NORM.S.DIST tính phân bố chuẩn chuẩn hóa có giá trị trung bình bằng 0 và độ lệch chuẩn bằng 1. Đây là trường hợp đặc biệt của phân bố chuẩn thường được sử dụng trong thống kê.
Cú pháp:
=NORM.S.DIST(z, cumulative)Hai tham số:
- z: Giá trị cần tính phân bố (thường là z-score đã chuẩn hóa)
- cumulative: Chọn TRUE hoặc FALSE để xác định loại kết quả
Tham số z chấp nhận bất kỳ số thực nào, bao gồm cả số âm. Nếu bạn nhập giá trị không phải số, hàm trả về lỗi #VALUE!. Tham số cumulative quyết định hàm sẽ tính hàm phân bố tích lũy hay hàm mật độ xác suất.
TRUE và FALSE tạo ra kết quả hoàn toàn khác nhau
Tham số cumulative quyết định bạn nhận được loại giá trị nào từ hàm. Đây là điểm quan trọng nhất khi làm việc với NORM.S.DIST.
Với cumulative = TRUE: Hàm trả về xác suất tích lũy, tức là xác suất để giá trị nhỏ hơn hoặc bằng z. Kết quả là một số từ 0 đến 1 đại diện cho diện tích dưới đường cong phân bố chuẩn bên trái giá trị z.
Ví dụ cụ thể:
=NORM.S.DIST(1.96, TRUE)Trả về 0.975 (tức 97.5%), nghĩa là 97.5% các giá trị trong phân bố chuẩn chuẩn hóa nhỏ hơn hoặc bằng 1.96.
Với cumulative = FALSE: Hàm trả về giá trị mật độ xác suất tại điểm z, tức là chiều cao của đường cong phân bố chuẩn tại vị trí đó. Kết quả này không phải là xác suất mà là giá trị của hàm mật độ.
=NORM.S.DIST(0, FALSE)Trả về 0.3989, đây là giá trị cao nhất của đường cong phân bố chuẩn tại điểm giữa.
Phần lớn các bài toán thống kê sử dụng TRUE để tính xác suất. FALSE chủ yếu dùng khi cần vẽ biểu đồ phân bố hoặc phân tích hình dạng đường cong.
Tính xác suất điểm kiểm tra của sinh viên
Giả sử bạn đang phân tích điểm kiểm tra của 500 sinh viên. Điểm trung bình là 70 với độ lệch chuẩn 10. Một sinh viên đạt 85 điểm và bạn muốn biết xác suất có sinh viên đạt điểm cao hơn 85.
Bước 1: Tính z-score Trước tiên cần chuẩn hóa điểm 85 thành z-score:
z = (85 - 70) / 10 = 1.5Bước 2: Áp dụng NORM.S.DIST
=NORM.S.DIST(1.5, TRUE)Kết quả: 0.9332 (93.32%)
Điều này có nghĩa là 93.32% sinh viên đạt điểm 85 hoặc thấp hơn. Vậy xác suất có sinh viên đạt điểm cao hơn 85 là:
1 - 0.9332 = 0.0668 (6.68%)Chỉ khoảng 6.68% sinh viên trong nhóm 500 người đạt điểm cao hơn 85. Phương pháp này nhanh hơn đáng kể so với việc tra bảng hoặc tính toán thủ công.
Phân tích chỉ số chất lượng trong sản xuất
Trong kiểm soát chất lượng sản xuất, NORM.S.DIST giúp xác định tỷ lệ sản phẩm đạt tiêu chuẩn. Giả sử bạn sản xuất ốc vít có đường kính tiêu chuẩn 10mm với dung sai ±0.3mm. Quy trình sản xuất có độ lệch chuẩn 0.15mm.
Tính xác suất sản phẩm đạt chuẩn:
Cận dưới: 9.7mm → z-score = (9.7 – 10) / 0.15 = -2
=NORM.S.DIST(-2, TRUE)Kết quả: 0.0228 (2.28% sản phẩm dưới chuẩn)
Cận trên: 10.3mm → z-score = (10.3 – 10) / 0.15 = 2
=NORM.S.DIST(2, TRUE)Kết quả: 0.9772 (97.72% sản phẩm trong khoảng từ -∞ đến 10.3mm)
Tỷ lệ sản phẩm đạt chuẩn = 0.9772 – 0.0228 = 0.9544 (95.44%)
Điều này có nghĩa là 95.44% sản phẩm nằm trong dung sai cho phép, còn 4.56% cần loại bỏ hoặc điều chỉnh quy trình.
So sánh với hàm NORM.DIST thường
NORM.S.DIST là trường hợp đặc biệt của hàm NORM.DIST tổng quát. Khi sử dụng NORM.DIST với giá trị trung bình = 0 và độ lệch chuẩn = 1, kết quả hoàn toàn giống NORM.S.DIST.
Hai công thức tương đương:
=NORM.S.DIST(1.5, TRUE)
=NORM.DIST(1.5, 0, 1, TRUE)Cả hai đều trả về 0.9332.
NORM.S.DIST ngắn gọn hơn khi làm việc với dữ liệu đã được chuẩn hóa thành z-score. Nếu dữ liệu của bạn có giá trị trung bình và độ lệch chuẩn khác 0 và 1, sử dụng NORM.DIST sẽ thuận tiện hơn vì không cần tính z-score thủ công.
Hàm NORM.S.DIST thay thế hàm NORMSDIST cũ từ Excel 2007 trở về trước. NORMSDIST vẫn hoạt động trong các phiên bản mới để tương thích ngược, nhưng chỉ tính phân bố tích lũy và không có tùy chọn FALSE cho mật độ xác suất.
Các lỗi thường gặp và cách khắc phục
Lỗi #VALUE! xuất hiện khi tham số z không phải là số. Điều này thường xảy ra khi ô tham chiếu chứa văn bản hoặc công thức trả về lỗi.
Kiểm tra:
=ISNUMBER(A1)Nếu trả về FALSE, ô A1 không chứa số. Đảm bảo dữ liệu đầu vào là số thực trước khi sử dụng NORM.S.DIST.
Nhầm lẫn giữa TRUE và FALSE là sai lầm phổ biến. Nếu kết quả của bạn là số rất nhỏ (dưới 0.5) trong khi mong đợi xác suất cao, có thể bạn đang dùng FALSE thay vì TRUE. Hầu hết các bài toán thống kê cần cumulative = TRUE để tính xác suất tích lũy.
Quên chuyển đổi sang z-score khi dữ liệu gốc không được chuẩn hóa. NORM.S.DIST yêu cầu đầu vào là z-score (giá trị đã trừ trung bình và chia cho độ lệch chuẩn). Nếu bạn nhập giá trị gốc trực tiếp, kết quả sẽ không chính xác.
Tương thích và phiên bản Excel
Hàm NORM.S.DIST có sẵn từ Excel 2010 trở đi, bao gồm Excel 2013, 2016, 2019, 2021 và Microsoft 365. Hàm hoạt động giống hệt nhau trên cả Windows và Mac.
Nếu đang sử dụng Excel 2007 hoặc cũ hơn, dùng hàm NORMSDIST thay thế nhưng lưu ý rằng hàm cũ không có tùy chọn cumulative và chỉ tính phân bố tích lũy. Để tính mật độ xác suất trên Excel 2007, cần sử dụng công thức thủ công phức tạp hơn.
Hàm NORM.S.DIST tương thích hoàn toàn với Google Sheets và các phần mềm bảng tính hỗ trợ chuẩn Excel. Cú pháp và kết quả hoàn toàn giống nhau trên các nền tảng này.