Hàm tính độ lệch chuẩn trong họ hàng STDEV có tới 6 phiên bản khác nhau. Hầu hết người dùng chỉ biết đến STDEV hoặc STDEVP, và dừng lại ở đó. Khi dữ liệu chứa văn bản hoặc giá trị logic như TRUE và FALSE, cả hai hàm này đều cho kết quả sai hoặc trả về lỗi. STDEVPA là hàm duy nhất xử lý được tình huống này.
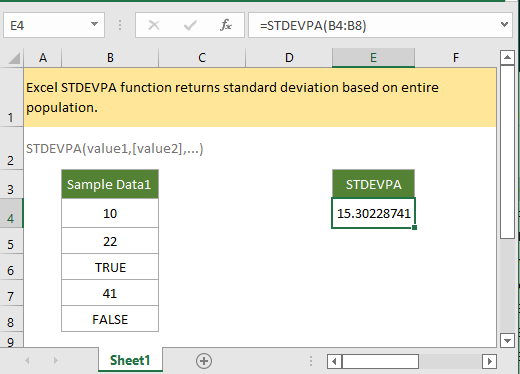
STDEVPA xử lý text và logic như số thực
Điểm đặc biệt của STDEVPA nằm ở cách nó đối xử với dữ liệu không phải số. Thay vì bỏ qua hoặc báo lỗi, hàm này chuyển đổi chúng thành giá trị số theo quy tắc cố định: văn bản bất kỳ trở thành 0, TRUE trở thành 1, và FALSE cũng trở thành 0. Điều này quan trọng khi làm việc với dữ liệu khảo sát, báo cáo có lỗi nhập liệu, hoặc bảng tính kết hợp nhiều loại dữ liệu.
Cú pháp cơ bản:
=STDEVPA(giá_trị1, [giá_trị2], ...)
Hàm chấp nhận tối đa 255 đối số. Mỗi đối số có thể là số, văn bản, giá trị logic, hoặc tham chiếu đến vùng ô chứa các giá trị này. Ô trống được bỏ qua hoàn toàn, không được tính là 0.
Khi nào text xuất hiện trong dữ liệu số
Tình huống phổ biến nhất là dữ liệu khảo sát. Một cột chấm điểm từ 1 đến 5 có thể chứa text “Không trả lời” hoặc “N/A” ở một số hàng. Hàm STDEVP sẽ bỏ qua những ô này hoàn toàn, khiến kết quả bị lệch vì cỡ mẫu thay đổi. STDEVPA tính chúng là 0, giữ nguyên số lượng dữ liệu.
Lỗi nhập liệu cũng tạo ra text không mong muốn. Người dùng gõ “10o” thay vì “100”, hoặc vô tình thêm dấu cách trước số. Những ô này trở thành text trong tính toán của hàm số học thông thường.
Ví dụ thực tế với dữ liệu khảo sát:
Giả sử đánh giá sản phẩm từ 5 khách hàng trong vùng A1:A5:
- A1: 4
- A2: 5
- A3: “Chưa dùng”
- A4: 3
- A5: 5
Công thức =STDEVP(A1:A5) chỉ tính 4 giá trị số (4, 5, 3, 5), cho kết quả 0.829. Công thức =STDEVPA(A1:A5) tính cả 5 giá trị (4, 5, 0, 3, 5), cho kết quả 1.939. Sự chênh lệch này rất lớn khi phân tích độ biến động của dữ liệu.
Giá trị logic TRUE và FALSE
Dữ liệu kiểu có/không, đúng/sai thường được lưu dưới dạng TRUE và FALSE trong các công thức điều kiện. Khi tính độ lệch chuẩn cho toàn bộ cột chứa cả kết quả logic và số, chỉ STDEVPA xử lý được.
Cách chuyển đổi:
- TRUE = 1
- FALSE = 0
- Text bất kỳ = 0
Quy tắc này áp dụng xuyên suốt. Một ô chứa công thức =10>5 trả về TRUE sẽ được STDEVPA đọc là 1. Một ô có text “TRUE” cũng được đọc là 0 vì nó là văn bản, không phải giá trị logic thực.
Ví dụ với dữ liệu logic:
Vùng B1:B6 chứa kết quả kiểm tra chất lượng:
- B1: TRUE (đạt chuẩn)
- B2: FALSE (lỗi)
- B3: TRUE
- B4: TRUE
- B5: FALSE
- B6: TRUE
Công thức =STDEVPA(B1:B6) chuyển thành tính độ lệch chuẩn của dãy (1, 0, 1, 1, 0, 1), cho kết quả 0.471. Đây là cách đo độ biến động của tỷ lệ đạt/không đạt trong quy trình sản xuất.
So sánh với STDEVP và STDEVA
STDEVP là hàm gốc tính độ lệch chuẩn cho toàn bộ tổng thể, nhưng bỏ qua hoàn toàn mọi văn bản và giá trị logic. Khi gặp text trong vùng dữ liệu, STDEVP chỉ đơn giản không tính ô đó. Điều này thay đổi cỡ mẫu và kết quả cuối cùng.
STDEVA cũng xử lý text và logic giống STDEVPA, nhưng dùng công thức mẫu (chia cho n-1 thay vì n). Sử dụng STDEVA khi dữ liệu chỉ là mẫu nhỏ từ tổng thể lớn hơn. STDEVPA dùng khi dữ liệu là toàn bộ tổng thể cần phân tích.
Bảng so sánh nhanh:
| Hàm | Xử lý text | Xử lý TRUE/FALSE | Công thức |
|---|---|---|---|
| STDEVP | Bỏ qua | Bỏ qua | n |
| STDEVPA | Đếm = 0 | TRUE=1, FALSE=0 | n |
| STDEVA | Đếm = 0 | TRUE=1, FALSE=0 | n-1 |
Sự khác biệt n và n-1 trong công thức tạo ra kết quả khác nhau đáng kể với bộ dữ liệu nhỏ. Với 10 giá trị, STDEVPA cho kết quả thấp hơn STDEVA khoảng 5 phần trăm.
Ba trường hợp cần dùng STDEVPA
Trường hợp 1: Dữ liệu khảo sát có câu trả lời văn bản
Khảo sát mức độ hài lòng từ 1-10 có thêm lựa chọn “Không ý kiến” hoặc “Chưa sử dụng”. Những câu trả lời này quan trọng cho phân tích vì chúng thể hiện một phần của tổng thể. Đếm chúng là 0 giúp giữ nguyên tỷ lệ phần trăm và cỡ mẫu.
Trường hợp 2: Lỗi nhập liệu cần phát hiện
Một cột số bị lẫn text do lỗi gõ. STDEVP im lặng bỏ qua các ô này, khiến người dùng không biết có vấn đề. STDEVPA tính chúng là 0, tạo ra kết quả khác thường và giúp phát hiện lỗi nhanh hơn.
Trường hợp 3: Kết hợp công thức logic với số
Cột tính toán có công thức IF trả về số hoặc text cảnh báo. Ví dụ: =IF(A1>100, A1, "Quá thấp"). Khi tính độ lệch chuẩn cho cột kết quả này, chỉ STDEVPA xử lý được cả số và text trong cùng một vùng.
Cách kiểm tra hàm nào đang được dùng
Mở file cũ hoặc nhận bảng tính từ người khác có thể chứa các công thức STDEV khác nhau. Cách nhanh nhất để kiểm tra là xem thanh công thức khi click vào ô chứa kết quả. Tên hàm xuất hiện rõ ràng ở đầu công thức.
Nếu file có hàng trăm công thức, dùng tính năng tìm kiếm. Nhấn Ctrl+F, chọn Options, tick Find All, và gõ “STDEV” vào ô tìm kiếm. Kết quả hiện toàn bộ ô sử dụng bất kỳ hàm nào trong họ STDEV. Click vào từng kết quả để xem công thức chi tiết.
Thay đổi từ STDEVP sang STDEVPA:
Chọn ô chứa công thức cũ, nhấn F2 để vào chế độ chỉnh sửa. Tìm text “STDEVP” trong thanh công thức, thêm chữ “A” vào cuối để thành “STDEVPA”. Nhấn Enter để cập nhật. Nếu có nhiều ô cần thay, dùng Find & Replace (Ctrl+H) để thay tất cả một lượt.
Lưu ý rằng kết quả sẽ thay đổi sau khi chuyển hàm nếu dữ liệu có chứa text hoặc logic. So sánh giá trị cũ và mới để đảm bảo sự thay đổi hợp lý với mục đích phân tích.
Lỗi thường gặp và cách xử lý
Lỗi divide by zero (#DIV/0!)
Xảy ra khi tất cả các ô trong vùng dữ liệu đều trống. STDEVPA cần ít nhất một giá trị số, text, hoặc logic để tính toán. Kiểm tra lại vùng tham chiếu có đúng không, hoặc dữ liệu có bị lọc ẩn hết.
Kết quả bằng 0
Xảy ra khi tất cả giá trị trong vùng giống hệt nhau. Ví dụ vùng A1:A10 đều chứa số 5, độ lệch chuẩn là 0 vì không có biến động. Điều này hoàn toàn bình thường và không phải lỗi.
Kết quả khác biệt lớn so với STDEVP
Nếu nhiều ô chứa text hoặc FALSE, việc chuyển chúng thành 0 sẽ kéo giá trị trung bình xuống thấp và làm tăng độ lệch chuẩn. Kiểm tra lại xem việc tính text là 0 có phù hợp với mục đích phân tích hay không. Đôi khi cần làm sạch dữ liệu trước thay vì dùng STDEVPA.
Khi nào không nên dùng STDEVPA
Dữ liệu hoàn toàn là số và không có khả năng lẫn text thì STDEVP đủ dùng và chạy nhanh hơn một chút. STDEVPA tốn thêm xử lý để kiểm tra từng ô xem có phải text hay logic không.
Dữ liệu là mẫu nhỏ từ tổng thể lớn thì dùng STDEVA thay vì STDEVPA. Công thức mẫu (n-1) cho ước lượng chính xác hơn khi không có toàn bộ dữ liệu. Ví dụ khảo sát 100 người từ tổng số 10000 người trong công ty.
Text trong dữ liệu thực ra là lỗi cần sửa chứ không phải thông tin hợp lệ. Trong trường hợp này tốt hơn là làm sạch dữ liệu bằng Find & Replace hoặc Text to Columns, rồi dùng STDEVP với dữ liệu đã sạch.
Tích hợp với các hàm khác
STDEVPA hoạt động tốt trong công thức lồng. Kết hợp với IF để tính độ lệch chuẩn có điều kiện: =IF(STDEVPA(A1:A10)>2, "Biến động cao", "Ổn định"). Hoặc dùng trong AVERAGEIF để so sánh độ lệch của các nhóm khác nhau.
Công thức phức tạp hơn là kết hợp STDEVPA với COUNTA để tính hệ số biến thiên: =STDEVPA(A1:A10)/AVERAGE(A1:A10)*100. Kết quả cho biết độ lệch chuẩn chiếm bao nhiêu phần trăm so với giá trị trung bình.
Công thức kiểm tra chất lượng dữ liệu:
=IF(COUNTA(A1:A100)<>COUNT(A1:A100), "Có text", "Toàn số")
Công thức này so sánh số ô có nội dung với số ô chứa số. Nếu khác nhau có nghĩa dữ liệu bị lẫn text. Đây là lúc cần xem xét dùng STDEVPA thay vì STDEVP.
Phiên bản Excel hỗ trợ
STDEVPA có mặt từ Excel 2000 trở đi, bao gồm tất cả phiên bản hiện đại như Excel 2016, 2019, 2021, và Microsoft 365. Hàm cũng hoạt động trên Excel for Mac và Excel Online. Không cần cập nhật hay kích hoạt tính năng gì thêm.
Các hàm STDEV cũ hơn như STDEV và STDEVP vẫn được giữ lại để tương thích ngược. Microsoft khuyến nghị dùng STDEV.S thay cho STDEV và STDEV.P thay cho STDEVP trong các file mới. Tuy nhiên STDEVPA vẫn giữ nguyên tên, không có phiên bản thay thế với dấu chấm.
Khi chia sẻ file cho người dùng Excel phiên bản cũ hơn năm 2000, cân nhắc thêm cột phụ chuyển đổi text thành số trước, rồi dùng STDEVP với cột đã chuyển đổi. Điều này đảm bảo file mở được trên mọi phiên bản.