Tính xác suất bằng tay với bảng tra phân phối chuẩn mất từ 5 đến 10 phút mỗi lần. Bạn phải tra giá trị Z, tìm hàng và cột tương ứng, rồi làm tròn kết quả. Hàm NORM.DIST trong Excel trả về kết quả chính xác trong 3 giây, tự động cập nhật khi dữ liệu thay đổi, và không cần nhớ công thức phức tạp.
Phân biệt hai chế độ của hàm
NORM.DIST có hai chế độ hoạt động hoàn toàn khác nhau thông qua tham số cumulative. Chế độ TRUE trả về xác suất tích lũy, còn FALSE trả về mật độ xác suất tại một điểm cụ thể.
Khi cumulative là TRUE, hàm tính xác suất một giá trị nhỏ hơn hoặc bằng x. Ví dụ với điểm thi trung bình 70 và độ lệch chuẩn 10, hàm sẽ cho biết bao nhiêu phần trăm học sinh đạt điểm dưới 80. Đây là chế độ được dùng nhiều nhất trong phân tích thống kê thực tế.
Cú pháp cho chế độ tích lũy:
=NORM.DIST(80, 70, 10, TRUE)Kết quả trả về 0.8413, nghĩa là 84.13% học sinh đạt điểm 80 trở xuống. Công thức này tự động tính tích phân từ âm vô cực đến giá trị x bạn nhập.
Chế độ FALSE tính giá trị của hàm mật độ tại điểm x. Thay vì tính diện tích dưới đường cong, nó cho biết độ cao của đường cong phân phối chuẩn tại điểm đó. Chế độ này ít dùng hơn, chủ yếu để vẽ đồ thị phân phối hoặc tính toán thống kê nâng cao.
=NORM.DIST(80, 70, 10, FALSE)Kết quả là 0.0242, đại diện cho giá trị mật độ xác suất tại điểm 80. Con số này không phải xác suất thực tế mà là tọa độ y trên đường cong phân phối.
Nhập các tham số đúng thứ tự
Hàm NORM.DIST yêu cầu bốn tham số theo thứ tự cố định. Nhập sai thứ tự sẽ cho kết quả hoàn toàn khác với mong đợi, và Excel không có cảnh báo lỗi nếu các giá trị vẫn hợp lệ về mặt toán học.
Cấu trúc đầy đủ:
=NORM.DIST(x, mean, standard_dev, cumulative)Tham số x là giá trị bạn muốn tính xác suất. Với bài toán về điểm thi, nếu muốn biết xác suất đạt điểm 85, x sẽ là 85. Mean là giá trị trung bình của toàn bộ dữ liệu, thường được tính bằng hàm AVERAGE hoặc cho trước trong đề bài.
Standard_dev là độ lệch chuẩn đo lường mức độ phân tán của dữ liệu. Tính bằng hàm STDEV.P cho toàn bộ tập dữ liệu hoặc STDEV.S cho mẫu dữ liệu. Tham số cumulative nhận giá trị TRUE hoặc FALSE, hoặc có thể dùng 1 và 0 tương ứng.
Ví dụ với tham chiếu ô:
=NORM.DIST(A2, B2, C2, TRUE)Trong đó A2 chứa giá trị x cần tính, B2 là trung bình, C2 là độ lệch chuẩn. Cách này tiện hơn khi cần tính nhiều giá trị hoặc khi dữ liệu thay đổi thường xuyên.
Áp dụng với dữ liệu thực tế
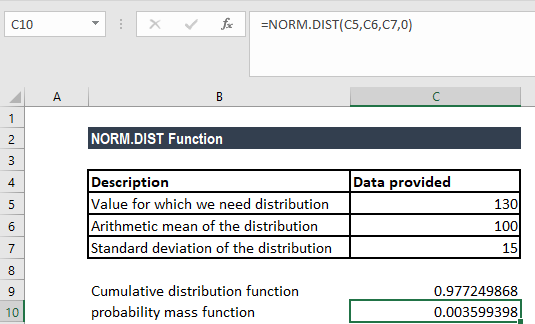
Giả sử bạn phân tích điểm thi IQ với giá trị trung bình là 100 và độ lệch chuẩn là 15. Một người bạn tuyên bố có IQ trên 130, và bạn muốn tính xác suất điều này xảy ra.
Đầu tiên tính xác suất IQ nhỏ hơn hoặc bằng 130:
=NORM.DIST(130, 100, 15, TRUE)Kết quả là 0.9772, có nghĩa 97.72% dân số có IQ từ 130 trở xuống. Để tính xác suất IQ trên 130, lấy 1 trừ đi kết quả này:
=1 - NORM.DIST(130, 100, 15, TRUE)Kết quả là 0.0228 hoặc 2.28%. Chỉ khoảng 2 trong 100 người có IQ trên 130, khá hiếm gặp.
Nếu muốn tính xác suất IQ đúng bằng 130 (không phải lớn hơn hay nhỏ hơn), dùng chế độ FALSE:
=NORM.DIST(130, 100, 15, FALSE)Kết quả khoảng 0.0035, cho thấy xác suất một người có IQ đúng bằng 130 là rất thấp. Đây là đặc điểm của phân phối liên tục, xác suất tại một điểm đơn lẻ luôn gần bằng 0.
Trong phân tích chứng khoán, hàm này giúp tính xác suất lợi nhuận vượt ngưỡng nhất định. Nếu lợi nhuận trung bình là 8% với độ lệch chuẩn 12%, xác suất lợi nhuận trên 15% được tính bằng:
=1 - NORM.DIST(15, 8, 12, TRUE)Xử lý các lỗi thường gặp
Lỗi VALUE xuất hiện khi bất kỳ tham số nào không phải là số. Excel không tự động chuyển đổi text thành số với hàm này, ngay cả khi text trông giống số như “100” trong dấu nháy kép.
Kiểm tra lỗi VALUE:
=ISNUMBER(A2)Nếu trả về FALSE, ô A2 chứa text hoặc công thức lỗi. Sử dụng VALUE để chuyển đổi:
=NORM.DIST(VALUE(A2), B2, C2, TRUE)Lỗi NUM xuất hiện khi độ lệch chuẩn nhỏ hơn hoặc bằng 0. Độ lệch chuẩn bằng 0 có nghĩa không có sự phân tán nào, tất cả giá trị giống nhau, làm cho phân phối chuẩn không có ý nghĩa.
=IF(C2<=0, "Lỗi: Độ lệch chuẩn phải > 0", NORM.DIST(A2, B2, C2, TRUE))Công thức này kiểm tra trước khi tính và hiển thị thông báo lỗi rõ ràng thay vì NUM.
Khi mean bằng 0, standard_dev bằng 1, và cumulative là TRUE, NORM.DIST tự động chuyển sang phân phối chuẩn hóa (standard normal distribution). Kết quả giống với hàm NORM.S.DIST:
=NORM.DIST(1.5, 0, 1, TRUE)
=NORM.S.DIST(1.5, TRUE)Cả hai công thức đều cho kết quả 0.9332. Dùng NORM.S.DIST ngắn gọn hơn khi làm việc với phân phối chuẩn hóa.
Tương thích và lựa chọn phiên bản
NORM.DIST có mặt từ Excel 2010 trở đi, bao gồm Excel 2013, 2016, 2019, 2021, và Microsoft 365. Hàm cũ NORMDIST vẫn hoạt động để đảm bảo tương thích ngược, nhưng Microsoft khuyến nghị chuyển sang NORM.DIST vì độ chính xác cao hơn.
Nếu file cần mở trên Excel 2007 hoặc cũ hơn, NORM.DIST sẽ hiển thị lỗi NAME. Trong trường hợp này, phải dùng NORMDIST với cú pháp giống hệt:
=NORMDIST(x, mean, standard_dev, cumulative)Khi làm việc với phân phối chuẩn hóa (mean = 0, standard_dev = 1), NORM.S.DIST ngắn gọn hơn và ít dễ nhầm lẫn hơn. Thay vì nhập bốn tham số, chỉ cần hai:
=NORM.S.DIST(z, cumulative)Trong đó z là giá trị đã được chuẩn hóa. Dùng hàm này khi làm việc với bảng Z hoặc khi đã có giá trị Z-score từ công thức (x – mean) / standard_dev.
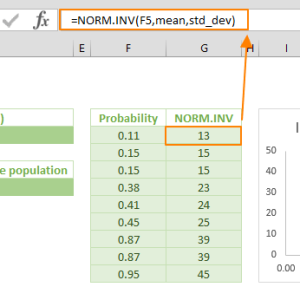
Hàm NORM.INV thực hiện thao tác ngược lại của NORM.DIST. Thay vì từ giá trị tìm xác suất, nó nhận xác suất và trả về giá trị tương ứng. Hữu ích khi cần tìm điểm cắt cho top 10% hoặc bottom 25% dữ liệu.