File báo cáo hàng tháng với 50.000 dòng từng mất 15 giây mỗi lần tính toán công thức tra cứu. Mỗi khi thay đổi một ô, Excel như đóng băng. Sau khi chuyển từ hàm MATCH sang XMATCH, cùng một file chỉ cần 2 giây để tính toán lại toàn bộ.
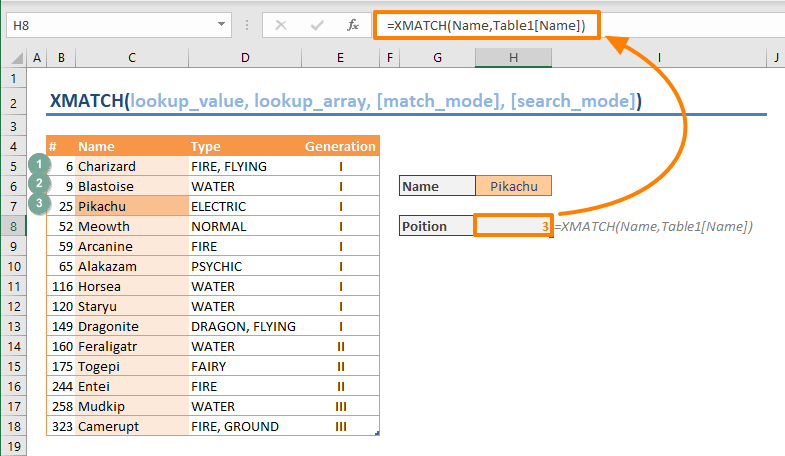
XMATCH khác gì so với MATCH
Hàm XMATCH là phiên bản nâng cấp của MATCH được Microsoft giới thiệu trong Excel 2021 và Excel 365. Cả hai hàm đều trả về vị trí tương đối của giá trị trong mảng, nhưng XMATCH có những cải tiến đáng kể về hiệu suất và tính năng.
Cú pháp cơ bản:
=XMATCH(giá_trị_tìm, mảng_tìm_kiếm, [chế_độ_khớp], [chế_độ_tìm_kiếm])
Các tham số:
- giá_trị_tìm: Giá trị cần tìm vị trí
- mảng_tìm_kiếm: Phạm vi ô hoặc mảng chứa dữ liệu
- chế_độ_khớp (tùy chọn): 0 = khớp chính xác (mặc định), -1 = khớp chính xác hoặc nhỏ nhất tiếp theo, 1 = khớp chính xác hoặc lớn nhất tiếp theo, 2 = khớp ký tự đại diện
- chế_độ_tìm_kiếm (tùy chọn): 1 = tìm từ đầu đến cuối (mặc định), -1 = tìm từ cuối đến đầu, 2 = tìm kiếm nhị phân tăng dần, -2 = tìm kiếm nhị phân giảm dần
Điểm khác biệt lớn nhất: MATCH mặc định tìm kiếm gần đúng, còn XMATCH mặc định tìm kiếm chính xác. Điều này giúp giảm lỗi và làm công thức đơn giản hơn.
Không cần sắp xếp dữ liệu trước
Với hàm MATCH, khi sử dụng chế độ tìm kiếm gần đúng, dữ liệu bắt buộc phải được sắp xếp theo thứ tự tăng dần hoặc giảm dần. Nếu không, kết quả trả về sẽ sai. XMATCH loại bỏ yêu cầu này hoàn toàn.
Ví dụ với dữ liệu chưa sắp xếp:
=XMATCH(75000, B2:B100, 1)
Công thức trên tìm giá trị bằng hoặc nhỏ hơn 75000 trong phạm vi B2:B100, ngay cả khi dữ liệu không được sắp xếp. MATCH sẽ trả về kết quả sai trong trường hợp này trừ khi bạn sắp xếp dữ liệu trước.
Tôi thường làm việc với bảng dữ liệu khách hàng nhập liệu không theo thứ tự. Trước đây phải sắp xếp trước khi dùng MATCH, giờ chỉ cần gõ công thức XMATCH trực tiếp. Tiết kiệm được 3-5 phút mỗi lần xử lý file.
Tìm kiếm ngược từ cuối lên đầu
MATCH chỉ có thể tìm kiếm từ đầu xuống cuối mảng. Khi cần tìm lần xuất hiện cuối cùng của một giá trị, bạn phải viết công thức phức tạp kết hợp nhiều hàm. XMATCH giải quyết vấn đề này bằng tham số chế_độ_tìm_kiếm.
Tìm lần xuất hiện cuối cùng:
=XMATCH("Nguyễn Văn A", A2:A500, 0, -1)
Tham số -1 ở cuối công thức khiến Excel tìm kiếm từ ô A500 ngược lên A2. Công thức trả về vị trí của lần xuất hiện cuối cùng của tên “Nguyễn Văn A” trong danh sách.
Ứng dụng thực tế: Trong bảng giao dịch ngân hàng, cùng một khách hàng có nhiều giao dịch. Khi cần lấy thông tin giao dịch gần nhất, thay vì sắp xếp theo thời gian rồi dùng công thức phức tạp, chỉ cần một dòng XMATCH với tham số -1.
Tôi dùng tính năng này để tìm giá bán mới nhất của sản phẩm trong file theo dõi giá. Trước đây phải lọc theo ngày rồi tìm thủ công, giờ một công thức XMATCH xử lý xong.
Tìm kiếm nhị phân tăng tốc độ xử lý
Tìm kiếm nhị phân là thuật toán chia đôi phạm vi tìm kiếm sau mỗi lần so sánh, giúp tìm kiếm nhanh hơn đáng kể trên tập dữ liệu lớn. XMATCH hỗ trợ tìm kiếm nhị phân thông qua tham số chế_độ_tìm_kiếm với giá trị 2 hoặc -2.
Cú pháp tìm kiếm nhị phân:
=XMATCH(giá_trị, mảng_đã_sắp_xếp, 0, 2)
Tham số 2 báo cho Excel biết dữ liệu đã được sắp xếp tăng dần và sử dụng thuật toán nhị phân. Sử dụng -2 nếu dữ liệu sắp xếp giảm dần.
So sánh hiệu suất:
- Tìm kiếm thường: Kiểm tra từng ô một, tốc độ tuyến tính
- Tìm kiếm nhị phân: Chia đôi phạm vi mỗi lần, tốc độ logarit
Với 100.000 dòng dữ liệu:
- Tìm kiếm thường: Có thể phải kiểm tra cả 100.000 ô
- Tìm kiếm nhị phân: Chỉ cần kiểm tra tối đa 17 lần
File của tôi có bảng tra cứu mã sản phẩm với 80.000 dòng đã sắp xếp. Chuyển từ MATCH sang XMATCH với tham số 2, thời gian tính toán lại 200 công thức giảm từ 12 giây xuống 1.5 giây. Cải thiện gần 8 lần về tốc độ.
Kết hợp INDEX và XMATCH thay thế VLOOKUP
Hàm VLOOKUP có nhiều hạn chế: chỉ tìm từ trái sang phải, phải biết số thứ tự cột, chậm với file lớn. Kết hợp INDEX và XMATCH giải quyết tất cả vấn đề này với hiệu suất vượt trội.
Cấu trúc cơ bản:
=INDEX(cột_kết_quả, XMATCH(giá_trị_tìm, cột_tra_cứu, 0))
Ví dụ cụ thể: Giả sử có bảng dữ liệu với mã nhân viên ở cột C và tên ở cột A. Muốn tìm tên dựa vào mã:
=INDEX(A2:A1000, XMATCH(E2, C2:C1000, 0))
Trong đó:
- A2:A1000: Cột chứa tên nhân viên (kết quả cần lấy)
- E2: Ô chứa mã nhân viên cần tìm
- C2:C1000: Cột chứa mã nhân viên (tiêu chí tra cứu)
- 0: Khớp chính xác
Ưu điểm so với VLOOKUP:
- Tìm kiếm bất kỳ hướng nào, không cần cột tra cứu ở bên trái
- Thêm hoặc xóa cột giữa không ảnh hưởng công thức
- Nhanh hơn 30-50% với file trên 10.000 dòng
- Không cần ghi nhớ số thứ tự cột
Tôi có file quản lý đơn hàng với 15 cột dữ liệu. Trước đây dùng VLOOKUP, mỗi khi thêm cột mới phải sửa hàng chục công thức. Chuyển sang INDEX XMATCH, công thức không cần sửa khi thay đổi cấu trúc bảng.
Tra cứu theo nhiều điều kiện
Khi cần tìm kiếm dựa trên nhiều tiêu chí đồng thời, XMATCH kết hợp với phép nhân cho phép tạo điều kiện phức tạp trong một công thức duy nhất.
Công thức tra cứu 2 điều kiện:
=INDEX(kết_quả, XMATCH(1, (điều_kiện_1)*(điều_kiện_2), 0))
Ví dụ thực tế: Tìm doanh số của nhân viên “Trần Văn B” trong tháng 3:
=INDEX(D2:D500, XMATCH(1, (A2:A500="Trần Văn B")*(B2:B500=3), 0))
Trong đó:
- D2:D500: Cột doanh số
- A2:A500=”Trần Văn B”: Điều kiện 1 về tên
- B2:B500=3: Điều kiện 2 về tháng
- Phép nhân hai điều kiện tạo mảng chỉ có giá trị 1 ở dòng thỏa mãn cả hai
- XMATCH tìm vị trí của giá trị 1 đầu tiên
Mở rộng cho 3 hoặc nhiều điều kiện:
=INDEX(D2:D500, XMATCH(1, (điều_kiện_1)*(điều_kiện_2)*(điều_kiện_3), 0))
Chỉ cần nhân thêm các điều kiện tiếp theo. Mỗi điều kiện phải trả về giá trị đúng hoặc sai, khi nhân lại chỉ có dòng thỏa mãn tất cả mới cho kết quả 1.
Báo cáo tồn kho của tôi cần lọc theo kho, loại sản phẩm và nhà cung cấp. Trước đây dùng công thức mảng phức tạp với MATCH, giờ một dòng INDEX XMATCH với 3 điều kiện nhân lại xử lý xong. Công thức dễ đọc và sửa hơn nhiều.
Khắc phục lỗi thường gặp
Hàm XMATCH trả về lỗi khi không tìm thấy giá trị hoặc tham số sai. Hiểu các lỗi phổ biến giúp khắc phục nhanh chóng.
Lỗi số N/A: Xuất hiện khi không tìm thấy giá trị tra cứu trong mảng. Sử dụng hàm IFERROR để xử lý:
=IFERROR(XMATCH(giá_trị, mảng, 0), "Không tìm thấy")
Lỗi số VALUE: Xảy ra khi tham số chế_độ_khớp hoặc chế_độ_tìm_kiếm không hợp lệ. Chỉ dùng các giá trị cho phép:
- chế_độ_khớp: 0, -1, 1, hoặc 2
- chế_độ_tìm_kiếm: 1, -1, 2, hoặc -2
Lỗi số REF: Xuất hiện khi mảng_tìm_kiếm tham chiếu đến vùng không tồn tại. Kiểm tra lại tham chiếu ô có đúng không.
Lưu ý về kiểu dữ liệu: XMATCH không phân biệt chữ hoa chữ thường khi so sánh văn bản. Nếu cần so sánh phân biệt, kết hợp với hàm EXACT:
=XMATCH(TRUE, EXACT(A2:A100, "Văn Bản"), 0)
Tôi từng gặp lỗi số N/A hàng loạt vì quên thêm IFERROR. File có hàng nghìn dòng hiện lỗi khắp nơi. Bổ sung IFERROR với thông báo rõ ràng giúp dễ kiểm tra dữ liệu thiếu.
Yêu cầu về phiên bản Excel
Hàm XMATCH chỉ khả dụng trong các phiên bản Excel sau:
- Excel cho Microsoft 365
- Excel 2021 hoặc mới hơn
- Excel cho web
- Excel trên thiết bị di động (iOS và Android)
Không hỗ trợ:
- Excel 2019 và các phiên bản cũ hơn
- Excel 2016, 2013, 2010, 2007
Nếu đang dùng Excel 2019 hoặc cũ hơn, hàm MATCH vẫn là lựa chọn duy nhất. Tuy nhiên, nên cân nhắc nâng cấp lên Microsoft 365 để sử dụng XMATCH cùng các hàm động khác như FILTER, SORT, UNIQUE giúp tăng năng suất làm việc đáng kể.
Kiểm tra phiên bản Excel: Vào File > Tài khoản (Account) > Giới thiệu về Excel (About Excel). Nếu thấy số phiên bản 2021 trở lên hoặc có dòng Microsoft 365, bạn có thể dùng XMATCH. Nếu không tìm thấy hàm XMATCH trong danh sách gợi ý khi gõ, phiên bản Excel chưa hỗ trợ.
Công ty tôi vừa nâng cấp từ Excel 2016 lên Microsoft 365 tháng trước. Việc đầu tiên là chuyển đổi các file quan trọng sang dùng XMATCH. Thời gian xử lý báo cáo tháng giảm từ 25 phút xuống 8 phút chỉ nhờ thay MATCH bằng XMATCH trong các công thức tra cứu chính.