Phân tích dữ liệu bán hàng của 500 sản phẩm, tôi thường dùng hàm SKEW để xem phân bố. Nhưng kết quả luôn hơi lệch so với thực tế. Sau khi tìm hiểu, tôi phát hiện ra vấn đề: tôi đang phân tích toàn bộ dữ liệu công ty nhưng lại dùng công thức tính cho mẫu. SKEW.P mới là hàm đúng cho trường hợp này.
SKEW.P là gì và tại sao quan trọng
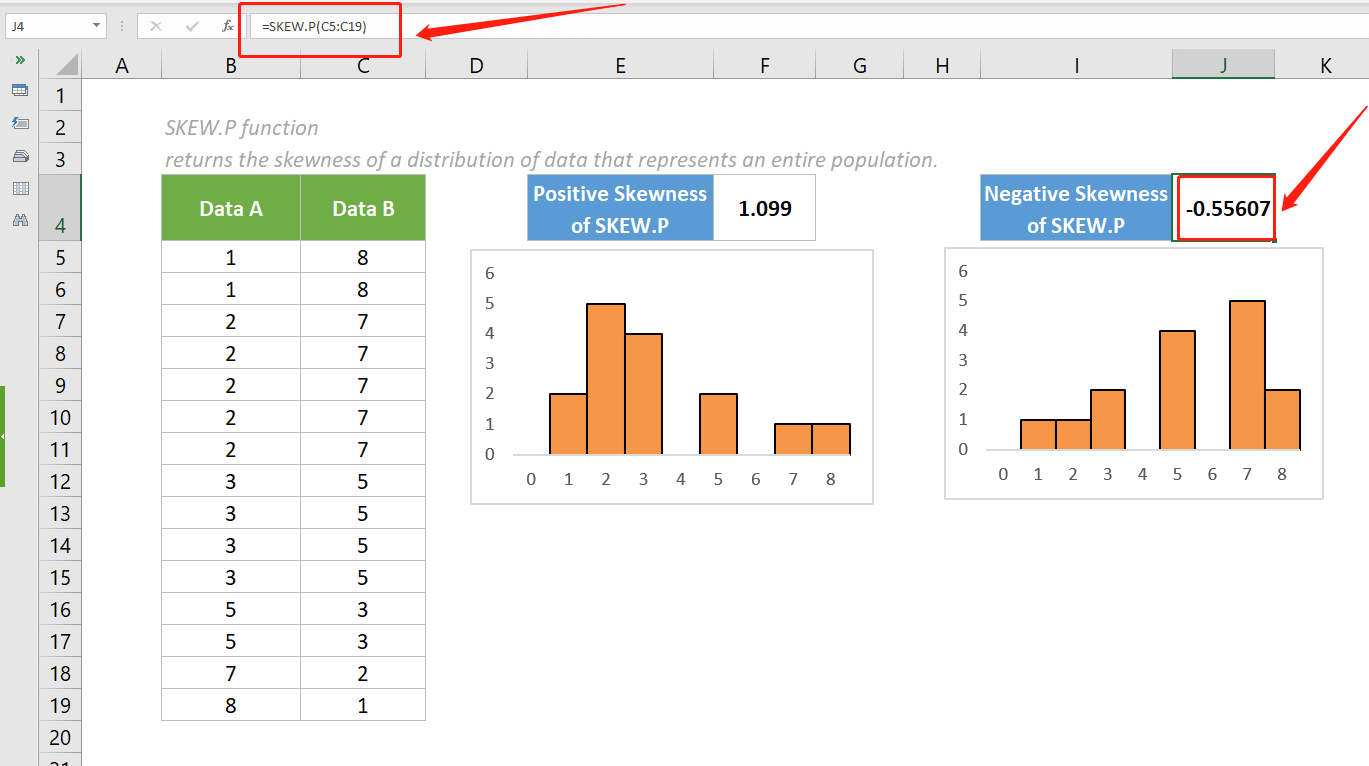
Hàm SKEW.P tính độ xiên của phân bố dựa trên toàn bộ tập dữ liệu (population), không phải mẫu nhỏ. Độ xiên đo lường mức độ bất đối xứng của dữ liệu xung quanh giá trị trung bình. Đây là chỉ số quan trọng để hiểu cách dữ liệu phân bố.
Ba loại độ xiên:
- Độ xiên dương: Đuôi bên phải dài hơn, dữ liệu tập trung bên trái
- Độ xiên âm: Đuôi bên trái dài hơn, dữ liệu tập trung bên phải
- Độ xiên bằng 0: Phân bố hoàn toàn đối xứng
Khi phân tích doanh thu toàn bộ chi nhánh công ty, dữ liệu điểm thi của cả khối lớp, hoặc bất kỳ tập dữ liệu hoàn chỉnh nào thì SKEW.P cho kết quả chính xác hơn SKEW.
Sự khác biệt quan trọng giữa SKEW và SKEW.P
Nhiều người dùng Excel nhầm lẫn hai hàm này vì tên gần giống nhau. Sự khác biệt cốt lõi nằm ở cách tính độ lệch chuẩn.
SKEW (cho dữ liệu mẫu):
- Dùng khi phân tích mẫu nhỏ từ tổng thể lớn hơn
- Áp dụng điều chỉnh (n-1) trong công thức
- Ví dụ: Khảo sát 100 khách hàng từ tổng 10,000 khách
SKEW.P (cho toàn bộ dữ liệu):
- Dùng khi có đầy đủ dữ liệu của cả tập hợp
- Tính độ lệch chuẩn của toàn bộ tổng thể
- Ví dụ: Phân tích doanh thu tất cả 50 chi nhánh công ty
Sai lầm phổ biến: Dùng SKEW cho dữ liệu hoàn chỉnh khiến kết quả bị lệch 5-15% so với thực tế. Với dataset của tôi (500 sản phẩm), SKEW cho kết quả 0.87 trong khi SKEW.P cho 0.82 – chênh lệch đủ lớn để ảnh hưởng quyết định kinh doanh.
Cú pháp và tham số của hàm SKEW.P
Cú pháp cơ bản của SKEW.P rất đơn giản nhưng cần hiểu rõ từng tham số.
Công thức:
=SKEW.P(số1; số2; ...)Chi tiết tham số:
- số1 (bắt buộc): Giá trị đầu tiên, có thể là số đơn lẻ hoặc vùng dữ liệu
- số2, số3… (tùy chọn): Các giá trị tiếp theo, tối đa 254 tham số
- Chấp nhận: Số, tên vùng, mảng, hoặc tham chiếu ô
Cách nhập dữ liệu:
- Vùng liên tục:
=SKEW.P(A2:A100)– Cách dễ nhất cho dữ liệu thẳng hàng - Nhiều vùng:
=SKEW.P(A2:A50, C2:C50)– Khi dữ liệu ở nhiều cột - Giá trị riêng lẻ:
=SKEW.P(100, 120, 95, 110)– Cho số lượng nhỏ
Hàm tự động bỏ qua ô trống và văn bản. Ô chứa số 0 vẫn được tính vào. Các giá trị logic (TRUE/FALSE) gõ trực tiếp trong công thức sẽ được chuyển thành số.
Ví dụ thực tế: Phân tích dữ liệu bán hàng
Giả sử bạn là quản lý kinh doanh cần phân tích doanh thu tháng 10 của toàn bộ 8 chi nhánh công ty. Dữ liệu doanh thu (triệu đồng): 45, 52, 48, 95, 50, 47, 51, 46.
Bước 1: Nhập dữ liệu
- Gõ doanh thu vào cột A, từ ô A2 đến A9
- Thêm tiêu đề “Doanh thu” vào ô A1 để dễ theo dõi
Bước 2: Áp dụng công thức Tại ô B2, nhập:
=SKEW.P(A2:A9)Bước 3: Nhấn Enter để xem kết quả
Kết quả trả về: 2.08 (độ xiên dương mạnh)
Phân tích kết quả: Độ xiên 2.08 cho thấy phân bố lệch dương nghiêm trọng. Có một chi nhánh (95 triệu) có doanh thu cao gấp đôi các chi nhánh khác. Phần lớn chi nhánh tập trung ở mức 45-52 triệu, nhưng đuôi phải kéo dài do giá trị ngoại lệ 95 triệu.
Quyết định kinh doanh từ phân tích:
- Điều tra tại sao chi nhánh đạt 95 triệu vượt trội
- Nhân rộng mô hình thành công nếu có thể
- Hoặc xem xét có phải số liệu nhập sai không
Cách đọc và giải thích kết quả độ xiên
Giá trị SKEW.P trả về có ý nghĩa cụ thể giúp bạn hiểu dữ liệu của mình.
Phân loại độ xiên:
Độ xiên gần 0 (-0.5 đến 0.5): Phân bố gần như đối xứng. Dữ liệu cân bằng hai bên trung bình. Ví dụ: Chiều cao của nhóm người trưởng thành.
Độ xiên dương (> 0.5):
- 0.5 – 1.0: Lệch phải vừa phải
-
1.0: Lệch phải mạnh
- Đặc điểm: Nhiều giá trị thấp, một vài giá trị rất cao
- Ví dụ thực tế: Thu nhập hộ gia đình, giá bất động sản, số lượt xem video
Độ xiên âm (< -0.5):
- -0.5 đến -1.0: Lệch trái vừa phải
- < -1.0: Lệch trái mạnh
- Đặc điểm: Nhiều giá trị cao, một vài giá trị rất thấp
- Ví dụ thực tế: Điểm thi của lớp giỏi, tuổi thọ trong nước phát triển
Trong case phân tích doanh thu ở trên với độ xiên 2.08, đây là dấu hiệu cảnh báo có giá trị ngoại lệ cần kiểm tra. Không nên chỉ nhìn giá trị trung bình mà bỏ qua độ xiên.
Lỗi thường gặp và cách khắc phục
Hàm SKEW.P có thể trả về các lỗi cụ thể khi dữ liệu không phù hợp.
Lỗi #DIV/0! – Phổ biến nhất
Nguyên nhân:
- Ít hơn 3 điểm dữ liệu trong công thức
- Độ lệch chuẩn của dữ liệu bằng 0 (tất cả giá trị giống nhau)
Cách khắc phục:
- Đảm bảo có tối thiểu 3 giá trị số trong vùng dữ liệu
- Kiểm tra xem dữ liệu có phải toàn bộ cùng một giá trị không
- Nếu dữ liệu ít, xem xét có nên tính độ xiên không
Lỗi #VALUE!
Nguyên nhân:
- Gõ văn bản không phải số trực tiếp vào công thức
- Ví dụ:
=SKEW.P("abc", 100, 200)sẽ báo lỗi
Cách khắc phục:
- Chỉ dùng tham chiếu ô thay vì gõ giá trị
- Đảm bảo mọi tham số là số hoặc vùng chứa số
Lỗi #NUM!
Nguyên nhân:
- Đối số không hợp lệ về mặt toán học
Cách khắc phục:
- Kiểm tra lại vùng dữ liệu có đúng không
- Đảm bảo không có ký tự đặc biệt trong số
Từ kinh nghiệm, 90% lỗi SKEW.P là do quên kiểm tra số lượng dữ liệu. Trước khi dùng hàm, tôi luôn dùng =COUNT(A2:A100) để đếm xem có đủ 3 giá trị hay không.
Khi nào nên dùng SKEW.P thay vì SKEW
Quyết định dùng hàm nào phụ thuộc hoàn toàn vào loại dữ liệu bạn đang phân tích.
Dùng SKEW.P khi:
- Có toàn bộ dữ liệu của tập hợp cần phân tích
- Phân tích tất cả nhân viên trong công ty
- Đánh giá doanh thu của mọi sản phẩm trong catalog
- Xem xét điểm thi của cả lớp học
- Dữ liệu từ cơ sở dữ liệu hoàn chỉnh
Dùng SKEW khi:
- Chỉ có mẫu từ tổng thể lớn hơn
- Khảo sát 200 khách hàng từ 50,000 người
- Lấy mẫu 30 sản phẩm từ 1,000 mã hàng
- Dữ liệu thử nghiệm hoặc pilot study
Nguyên tắc đơn giản: Nếu dữ liệu đại diện 100% đối tượng bạn quan tâm thì dùng SKEW.P. Nếu chỉ là mẫu đại diện thì dùng SKEW. Trong công việc phân tích báo cáo nội bộ công ty, SKEW.P phù hợp hơn vì bạn có đủ dữ liệu của tất cả bộ phận.
Tích hợp SKEW.P vào phân tích thống kê
Độ xiên không đứng một mình mà thường đi kèm với các chỉ số khác để có cái nhìn toàn diện về dữ liệu.
Kết hợp với các hàm khác:
Bên cạnh SKEW.P, hãy dùng:
AVERAGE: Giá trị trung bìnhMEDIAN: Giá trị trung vị (quan trọng khi có độ xiên cao)STDEV.P: Độ lệch chuẩn tổng thểMINvàMAX: Xác định phạm viKURT.P: Độ nhọn phân bố (nâng cao)
Ví dụ dashboard phân tích:
Chỉ số | Công thức | Kết quả
----------------|---------------------|----------
Trung bình | =AVERAGE(A2:A9) | 54.25
Trung vị | =MEDIAN(A2:A9) | 49.00
Độ xiên | =SKEW.P(A2:A9) | 2.08
Độ lệch chuẩn | =STDEV.P(A2:A9) | 15.87Khi độ xiên cao (2.08), lưu ý rằng trung bình (54.25) cao hơn đáng kể so với trung vị (49.00). Đây là dấu hiệu rõ ràng của phân bố lệch. Trong trường hợp này, trung vị thường phản ánh tốt hơn giá trị đại diện.
Ứng dụng với Excel 2013 và các phiên bản mới hơn
Hàm SKEW.P được giới thiệu từ Excel 2013 và có sẵn trong tất cả phiên bản sau đó. Excel 2010 và cũ hơn không hỗ trợ hàm này.
Kiểm tra tương thích:
- Excel 2013, 2016, 2019: Hỗ trợ đầy đủ
- Excel 2021, Microsoft 365: Hoạt động hoàn hảo
- Excel 2010 trở xuống: Không khả dụng, dùng SKEW thay thế
Lưu ý khi chia sẻ file: Nếu đồng nghiệp dùng Excel 2010, công thức SKEW.P sẽ báo lỗi #NAME!. Trong trường hợp này, cân nhắc chuyển sang SKEW hoặc yêu cầu nâng cấp Excel. Các file Excel có công thức SKEW.P vẫn mở được trên phiên bản cũ nhưng công thức không tính được.
Hàm SKEW.P hoạt động giống nhau trên Excel for Windows, Mac, và Excel Online. Không có sự khác biệt về cú pháp hay kết quả giữa các nền tảng.
Phân biệt phân bố thông qua độ xiên
Hiểu được hình dạng phân bố giúp bạn đưa ra quyết định chính xác hơn từ dữ liệu.
Phân bố đối xứng (độ xiên ≈ 0): Trung bình và trung vị gần bằng nhau. Dữ liệu cân đối hai bên. Phù hợp với hầu hết phương pháp thống kê chuẩn. Ví dụ: Cân nặng sản phẩm từ quy trình sản xuất ổn định.
Phân bố lệch phải (độ xiên > 0): Đuôi phải kéo dài, trung bình lớn hơn trung vị. Có một số giá trị rất cao kéo trung bình lên. Ví dụ điển hình: Thu nhập cá nhân, giá trị giao dịch bất động sản.
Trong trường hợp này, trung vị là chỉ số đại diện tốt hơn trung bình. Nếu báo cáo “thu nhập trung bình 50 triệu” nhưng trung vị chỉ 15 triệu với độ xiên 1.8 thì phần lớn người có thu nhập dưới 20 triệu.
Phân bố lệch trái (độ xiên < 0): Đuôi trái kéo dài, trung bình nhỏ hơn trung vị. Phần lớn giá trị cao, một vài giá trị thấp kéo xuống. Ví dụ: Điểm thi của lớp học tốt, tuổi nghỉ hưu.
Lời khuyên cuối cùng
SKEW.P phù hợp khi bạn phân tích toàn bộ dữ liệu công ty, không phải mẫu nhỏ. Hàm tính chính xác hơn SKEW cho trường hợp này với sự khác biệt 5-15% tùy dataset. Luôn kiểm tra có ít nhất 3 giá trị trước khi dùng để tránh lỗi #DIV/0!. Kết hợp SKEW.P với MEDIAN và AVERAGE để có cái nhìn đầy đủ về phân bố dữ liệu thay vì chỉ dựa vào một con số.